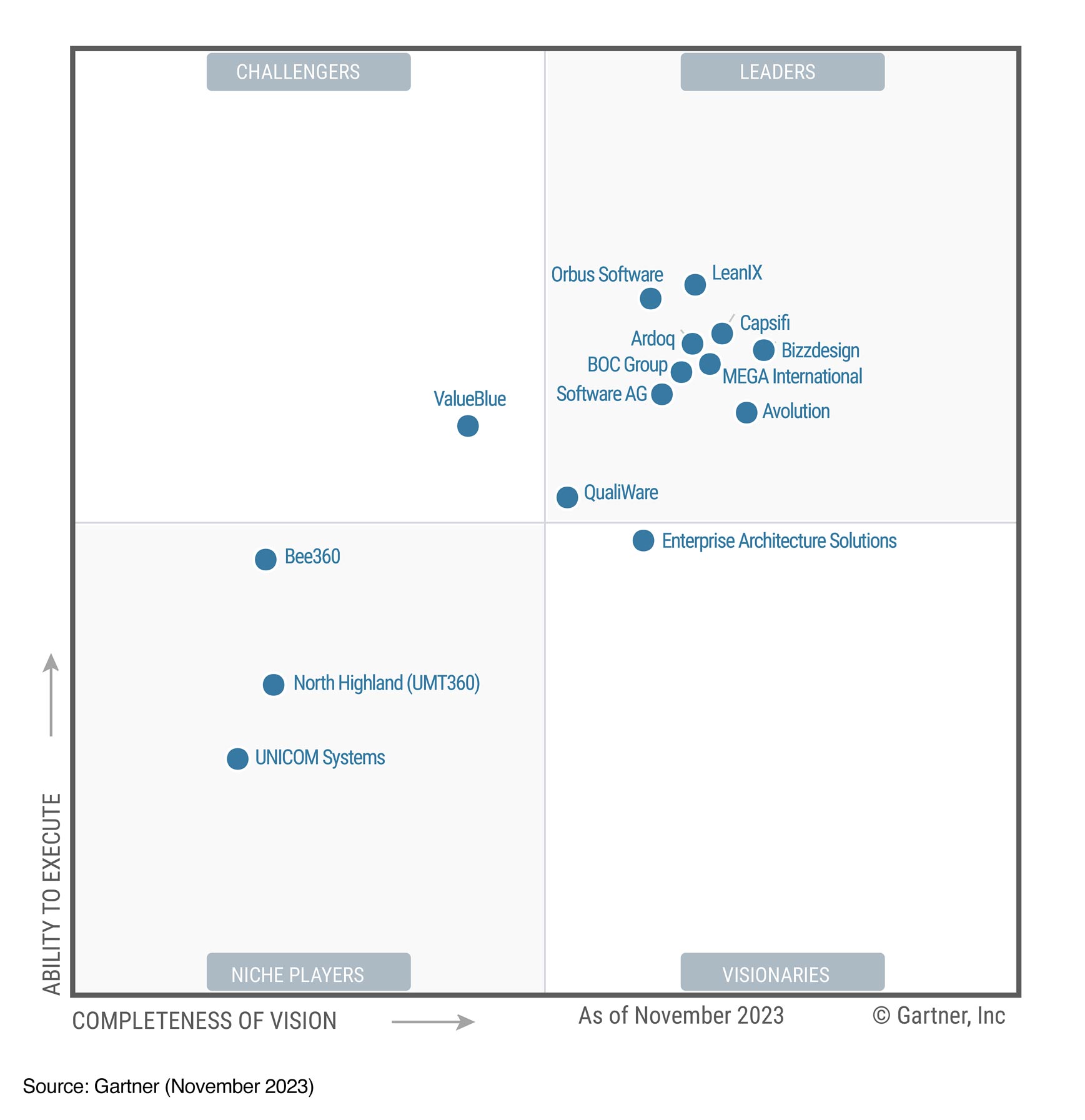



Recognized as a Leader by Gartner and used by thousands of satisfied users at leading enterprises, our Bizzdesign Horizzon software combines powerful data integration and a central ‘insight graph’ with current to future state modelling, roadmapping and real time analytics in a single secure and flexible collaborative business design and change platform supporting all key frameworks. It unifies strategy, capabilities, operating models and change portfolios. Giving you the insights to make the right investments decisions (“do the right things”) and then helping you connect them with all moving parts for successful execution (“do things right”).
We help unleash the full potential of the enterprise.
By breaking through silos and bringing disciplines and data around a shared language and version of the truth. Think of us as the “Rosetta Stone” of successful collaboration for change.




Describing processes and system interactions works very efficiently. The views provide a complete overview to easily access documentation. Through modeling, all components are much more transparent.
I believe that all organizations, if they’re serious about implementing change, should start by carefully assessing their change agents. Good people will find a way. They’ll bring in the platform that’s needed to deliver a journey of change for replacing new standards, process and tools to increase the impact of EA at the bank.
Using a solution like Horizzon and employing enterprise architecture techniques enabled us to achieve a clear understanding of the most important business services and successfully map out their dependencies across various dimensions of the enterprise – people, processes, technology, place.
Bizzdesign Enterprise Studio allows us to integrate every kind of information, making the repository our complete body of knowledge; our single source of truth. Kees Tuijnman, Athora Insurance
Having a business capabilities model is good to have in times of stability, slow change. But it is very, very important to have in a time of business transformation.